Lesson 18: Wrapping up and looking ahead
Today is our second-to-last class!
Course evaluations
Please complete the course evaluations when they become available at the end of the semester
Unfortunately, we will not be able to get our course evaluations until the end of the semester. Students formally enrolled (both for credit or audit) should get an email with a link to the evaluation at that time, and I would really appreciate it if you can take a few minutes to answer the questions.
This course is still under very active development, so I would really value everybody’s feedback on how we can improve it and make it as useful as possible.
Please share your candid thoughts and suggestions in the evaluation. Remember that all comments are completely anonymous and I only get to see it after S/U decisions have been submitted.
If anyone has feedback or suggestions they would like to share right away, we would be happy to hear your thoughts! You can either private message, email, or post in the feedback channel on Slack. Remember you can post anonymously by prefacing your message with /anon (e.g. `/anon Here is my message).
Agenda for today’s class
- Quick review
- Continued access to the course material
- Fork or clone a copy of our course repo if you want a permanent copy of the course notes
- Zoom recordings will remain available for 120 days on Canvas. You can download any videos you would like to keep
- Important take-home messages and a review of good practices
- Where to learn more and connect with the R user community
Good practices
1. Keep your raw data raw
Resist the temptation to manually edit or reformat your original file because if your documentation of the changes is imperfect, you may lose important information. Clean up the data in R. Your R code, along with appropriate documentation will be a record of the changes. The code can be modified and rerun, using the raw data file as input, if needed.
2. Make sure all your processing steps are included in your scripts and test that your code can run in a new environment
Make sure that your code does not rely on objects or functions defined outside of your script. If that is the case, it can’t readily be run by yourself or someone else in the future.
Make sure to frequently re-start R as you’re working, as elaborated on by Jenny Bryan here.
Also, if you haven’t already, follow the instructions from r4ds on how ensure that RStudio does not restore your workspace between sessions, so you start with a clean environment every time. Make sure this option is selected under your RStudio preferences:
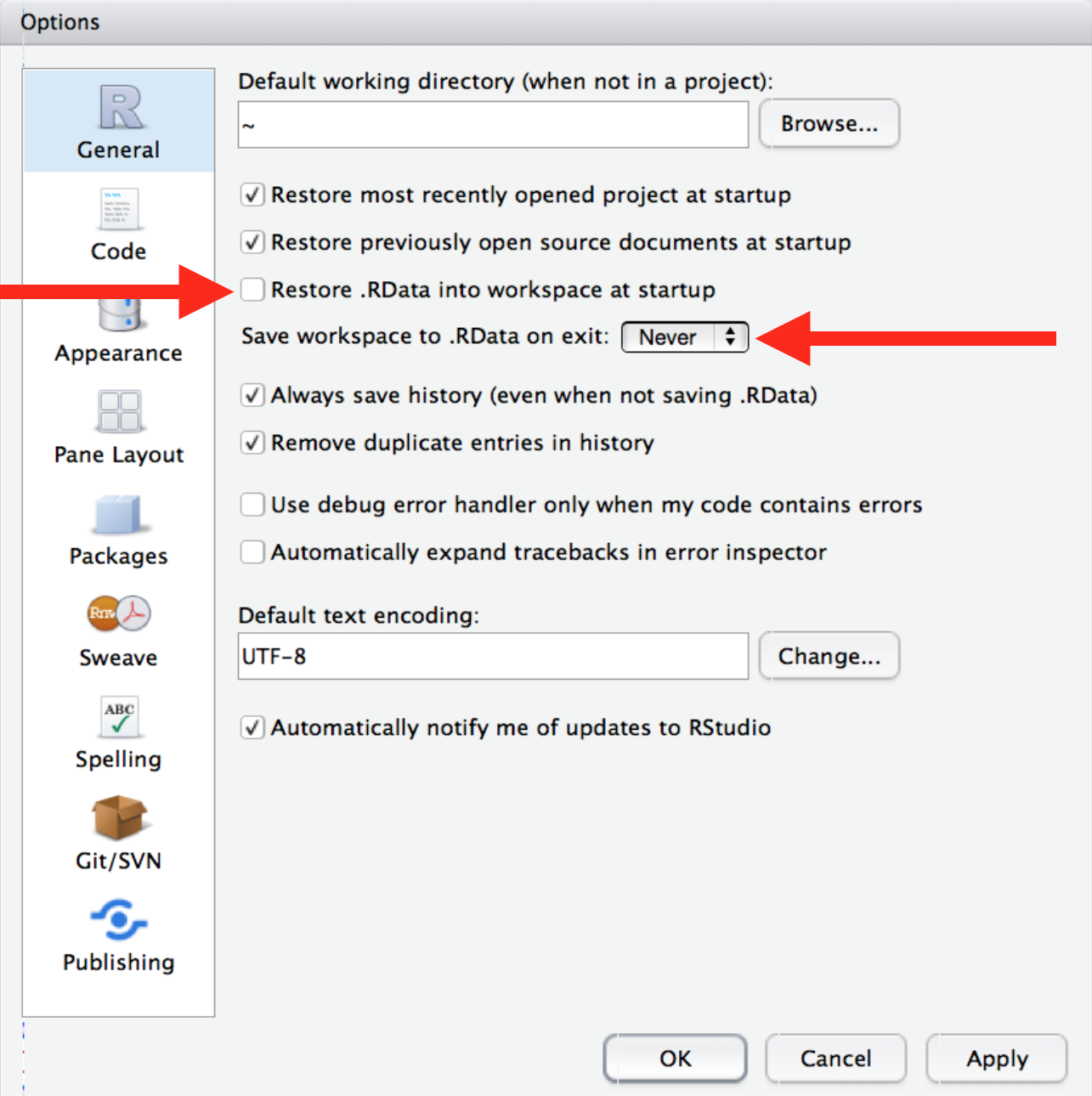
Slides from Deep thoughts by Jenny Bryan:


3. Organizing your work into R projects within RStudio makes life easier
Organizing your work into RStudio projects avoids issues with absolute file paths and makes it easier to keep track of the code used to generate plots and reports, share your code with others, and work on multiple different projects in parallel. Not convinced yet? Check out What they forgot to teach you about R
4. Explain and document your thought process with notes and comments
Document the big-picture structure both within files (comments) and between files (README’s). In general, comments (and Git commit messages) should explain the why not the what (which should be self-evident from well-written code). Can a collaborator or you-in-six-months quickly figure out what’s going on in your code?
5. Develop a consistent coding style that maximizes readability
Developing a consistent style in your coding, makes it a lot easier to read. Here is some inspiration:
- The tidyverse style guide
- A more concise overview of the style Hadley Wickham uses in his books “R for Data Science” and “Advanced R”
- There are also great tips for styling, organizing and optimizing your code in the blogpost R Best Practices: R you writing the R way! by Milind Paradkar
- Many of the same principles are also summarized by JEFworks here
6. “Write code for humans, write data for computers”
Very important advice from Vince Buffalo
Some ways to make code more human-readable include:
- Clear workflows
- Use comments
- Give objects meaningful names
- Use well-named operations, e.g.
select(data, columnname)instead ofdata[,5]
7. Make your data tidy
An important principle for “writing data for computers” is to clean up and reshape your data into tidy format for analysis. That way, you can take advantage of the powerful set of tools available in the tidyverse and beyond instead of having to invent your own roundabout approaches, and this will both make your code more robust, concise, and readable. As a reminder, have another look at the Openscapes tidy data blog post
Resources for learning more
R and the tidyverse
- R for Data Science by Garrett Grolemund and Hadley Wickham. See also answers to the exercises here and other places you can find on google and a dedicated R4DS Slack workspace for community learning. [I strongly recommend working through the chapters of this book that we have not covered]
- Advanced R by Hadley Wickham
- What they forgot to teach you about R by Jenny Bryan and Jim Hester
- R for the Rest of Us - Resources page - a curated list of excellent tutorials
- Course notes for STAT545 by Jenny Bryan
- Practical Data Science for Stats - a PeerJ Collection
- ggplot2: Elegant Graphics for Data Analysis by Hadley Wickham
- swirl: learn R, in R - a platform for learning R programming and data science interactively, at your own pace, and right in the R console
Here are a few other books you might want to check out:
- A ModernDive into R and the tidyverse by Chester Ismay and Albert Y. Kim
- Introduction to Data Science: Data Analysis and Prediction Algorithms with R by Rafael A. Irizarry
- The R Cookbook by James Long and Paul Teetor (primarily base-R, but also uses some tidyverse packages/functions)
And for getting help, check out the slide deck or recorded talk for Jenny Bryan’s talk “Object of type ‘closure’ is not subsettable” at the 2020 RStudio conference. You can also check out her Reprex webinar.
RMarkdown
- RMarkdown for Scientists by Nicholas Tierney
- R Markdown: The Definitive Guide by Yihui Xie, J. J. Allaire, and Garrett Grolemund
GitHub
- Happy Git and GitHub for the useR by Jenny Bryan
- If you want to get started with command line workflows, the Software Carpentry Lesson on Git is a good place to start
Open practices in environmental data science
- Check out and follow developments at Openscapes, an awesome organization led by Julia Stewart Lowndes aimed at empowering environmental scientists to do better science in less time through open and collaborative practices.
More cool R applications
Dashboards:
Check out the Dashboard developed for the continually updated Coronavirus dataset we worked with earlier in the course. Note that you can grab all the code under Source code in the top right corner.
Dashboards can also be made interactive with dynamic and user-controlled displays of data through use of Shiny, an R package that makes it easy to build interactive web apps straight from R.
For an example, check out this dynamic visualization of the gapminder dataset we worked with in our last class (make sure to check out the cool video with Hans Rosling)
Shiny let’s you create similar interactive displays. See for example a very simple example here, and materials for building a more advanced version here
For more examples, check out the RStudio Flexdashboard website. And check out Mastering shiny by Hadley Wickham
Connecting with the R stats community
NTRES-6100 alums Slack Channel - a low-pressure environment where you can continue to support each other and share resources. We will send an invite on Slack
Tips on how to start engaging on twitter from R for Excel Users by Julia Lowndes and Allison Horst
Finding the YOU in the R community by Thomas Mock
Exercise
Go to the RStudio Tips twitter account (https://twitter.com/rstudiotips) and find one tip that looks interesting. Practice using it!
Here is an example of recent very useful thread, listing RStudio shortcuts
Take-home messages
From the Ocean Health Index Data Science Training:
Three messages
If there are 3 things to communicate to others after this course, I think they would be:
1. Data science is a discipline that can improve your analyses
- There are concepts, theory, and tools for thinking about and working with data.
- Your study system is not unique when it comes to data, and accepting this will speed up your analyses.
This helps your science:
- Think deliberately about data: when you distinguish data questions from research questions, you’ll learn how and who to ask for help
- Save heartache: you don’t have to reinvent the wheel
- Save time: when you expect there’s a better way to do what you are doing, you’ll find the solution faster. Focus on the science.
2. Open data science tools exist
- Data science tools that enable open science are game-changing for analysis, collaboration and communication.
- Open science is “the concept of transparency at all stages of the research process, coupled with free and open access to data, code, and papers” (Hampton et al. 2015))
This helps your science:
- Have confidence in your analyses from this traceable, reusable record
- Save time through automation, thinking ahead of your immediate task, reduced bookkeeping, and collaboration
- Take advantage of convenient access: working openly online is like having an extended memory
3. Learn these tools with collaborators and community (redefined):
- Your most important collaborator is Future You.
- Community should also be beyond the colleagues in your field.
- Learn from, with, and for others.
This helps your science:
- If you learn to talk about your data, you’ll find solutions faster.
- Build confidence: these skills are transferable beyond your science.
- Be empathetic and inclusive and build a network of allies
If we have time: Discussion questions as warm-up for Wednesday’s presentations
- What is the most valuable thing you have learned in this class?
- Are you planning to implement any changes your workflow or practices moving forward
- What are you excited about learning next or what existing skills do you want to improve?